Os Métodos de Monte Carlo (MMC) são uma técnica poderosa que utiliza a simulação de valores aleatórios para calcular aproximações de valores esperados e integrais que não podem ser resolvidos analiticamente. Neste contexto, aprendemos a utilizar variáveis aleatórias simuladas para realizar o cálculo aproximado de integrais.
Seja \(X\) uma v.a. discreta com função de probabilidade \(p(x)\) ou uma v.a. contínua com função densidade \(f(x)\). O Método de Monte Carlo propõe um estimador para \[
\theta = \mathbb{E}[g(X)] = \begin{cases}
\int_{-\infty}^{\infty} g(x) f(x) \, dx & \text{se $X$ é contínua} \\
\sum_x g(x) p(x) & \text{se $X$ é discreta}
\end{cases}
\]
Especificamente, ele funciona da seguinte forma. Seja \(X_1, \dots, X_n\) uma sequência de variáveis aleatórias i.i.d. com a mesma distribuição que \(X\). Então:
O método de Monte Carlo funciona devido à Lei Forte dos Grandes Números, que garante que a média amostral convergirá quase certamente para a esperança verdadeira conforme o número de amostras tende ao infinito:
Assim, quando \(n\) cresce, a estimativa de Monte Carlo converge para o verdadeiro valor de \(\theta\).
Importante: Frenquentemente \(n\) é denotado por \(B\) na literatura de Monte Carlo, de forma a não haver confusão com o tamanho de amostras não geradas no computador.
11.1 Exemplo 1: Estimativa de uma Integral
Queremos obter uma estimativa para
\[
\theta = \int\limits_{0}^{1}e^{-x} dx
\]
Para isso, basta observar que se \(U \sim Unif(0,1)\), então \(\theta = \mathbb{E}[e^{-U}]\). De fato, se \(U \in Unif(0,1)\), \[
\theta=\int\limits_{0}^{1}e^{-x} dx= \int\limits_{0}^{1}e^{-u}f(u) du.
\] Assim, o estimador desta integral via MMC pode ser obtido da seguinte forma:
n <-100u <-runif(n, min =0, max =1)# Estimativa de theta usando Monte Carlotheta_hat <-mean(exp(-u))cat("Estimativa de theta_hat:", theta_hat, "\n")
Estimativa de theta_hat: 0.6630753
Mostrar código
# Valor real da integralvalor_real <-1-exp(-1)cat("Valor real:", valor_real, "\n")
Valor real: 0.6321206
Mostrar código
import numpy as np# Número de amostrasn =100# Geração de amostras uniformesu = np.random.uniform(0, 1, n)# Estimativa de theta usando Monte Carlotheta_hat = np.mean(np.exp(-u))print("Estimativa de theta_hat:", theta_hat)
Estimativa de theta_hat: 0.6448094381433137
Mostrar código
# Valor real da integralvalor_real =1- np.exp(-1)print("Valor real:", valor_real)
Valor real: 0.6321205588285577
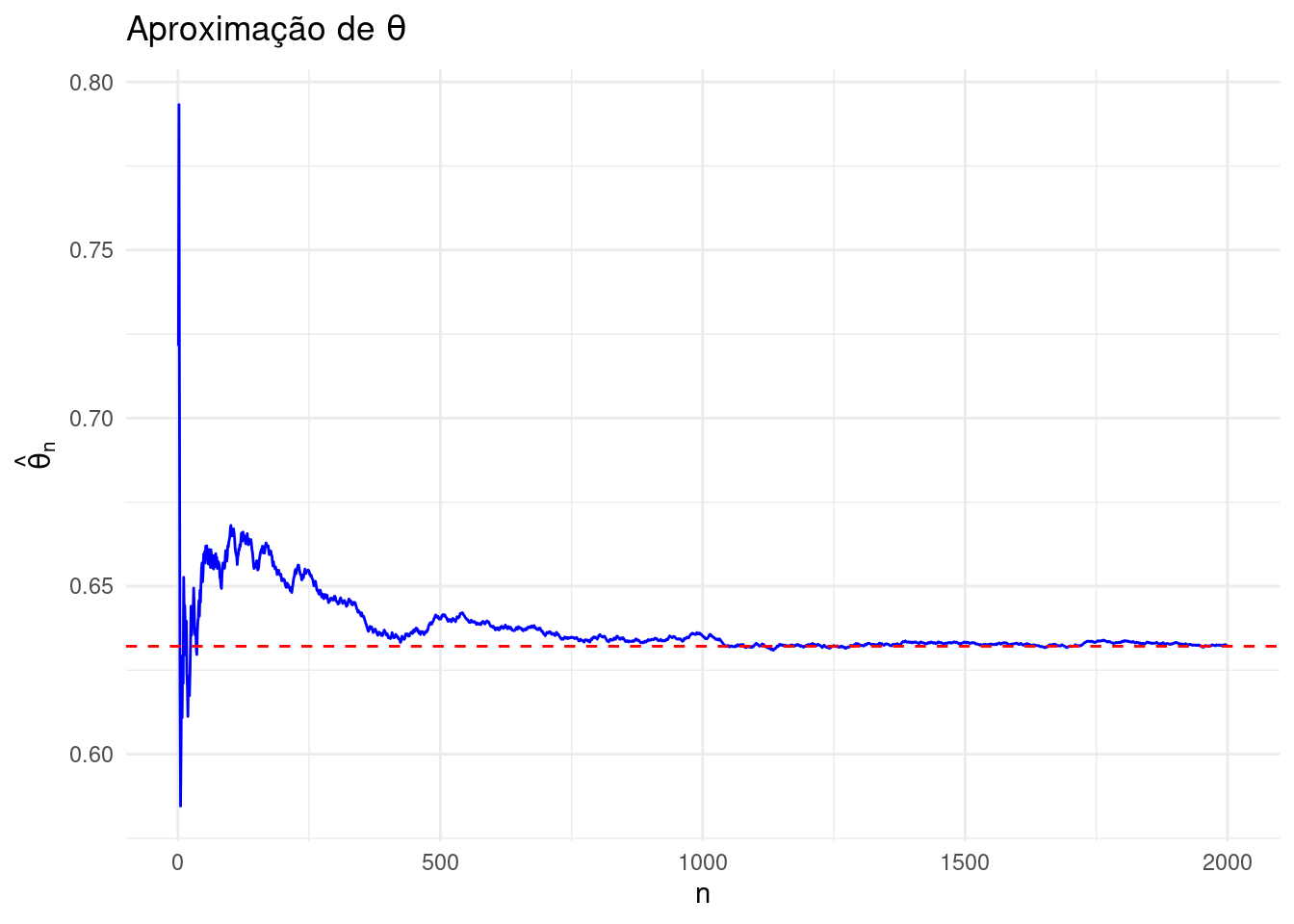
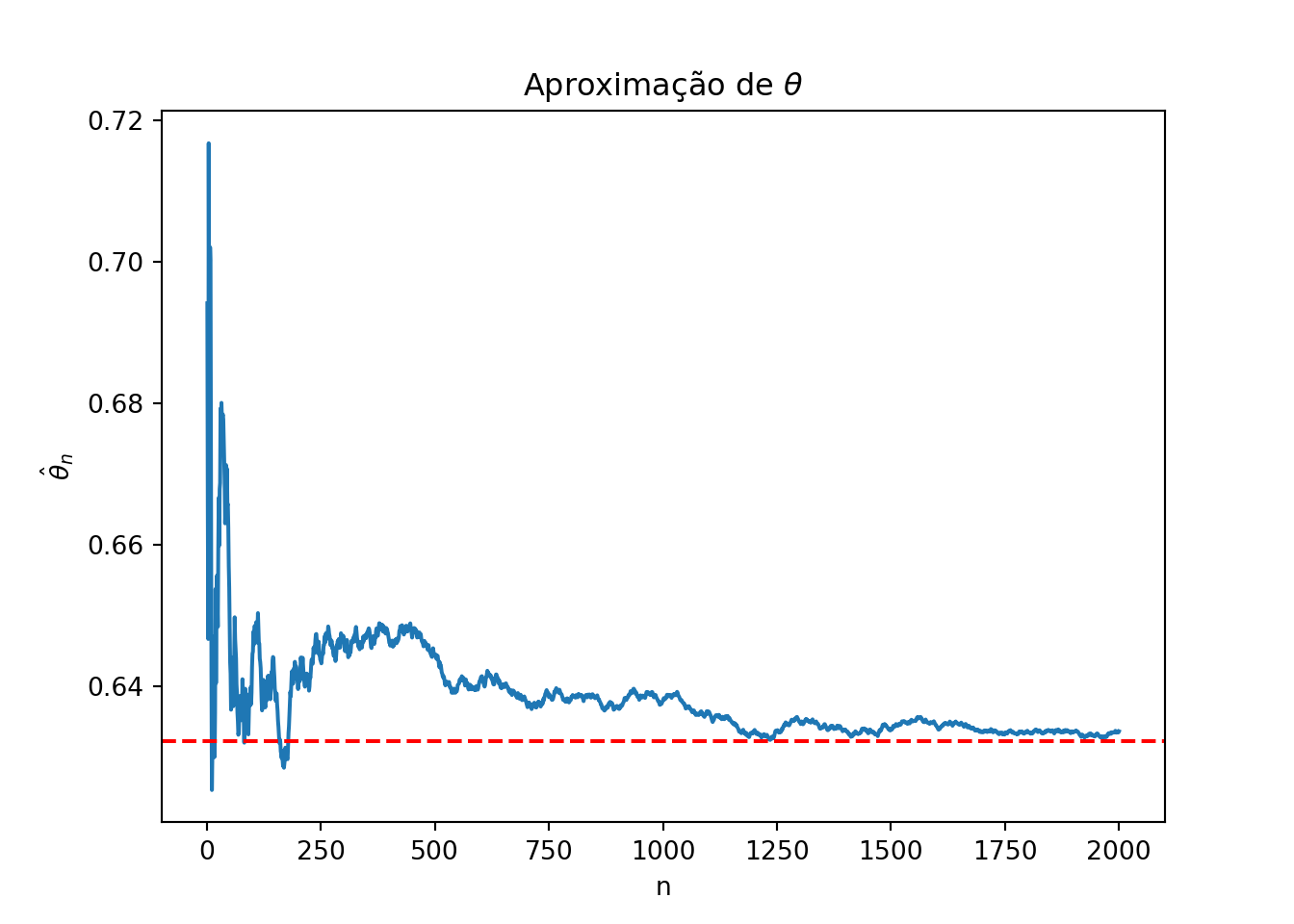
Vamos verificar como o valor de \(n\) influencia na aproximação:
library(ggplot2)set.seed(58)N <-1:2000theta_hat <-numeric(length(N))u <-numeric(length(N)) # Pré-alocação do vetor# Preenchendo o vetor u e calculando theta_hatfor (i inseq_along(N)) { u[i] <-runif(1) theta_hat[i] <-mean(exp(-u[1:i]))}# Criando o dataframe para o ggplotdf <-data.frame(N = N, theta_hat = theta_hat)# Plotar o gráfico usando ggplot2ggplot(df, aes(x = N, y = theta_hat)) +geom_line(color ="blue") +geom_hline(yintercept =1-exp(-1), color ="red", linetype ="dashed") +labs(x ="n", y =expression(hat(theta)[n]), title =expression(Aproximação~de~theta)) +theme_minimal()
Mostrar código
import numpy as npimport matplotlib.pyplot as pltnp.random.seed(58)N = np.arange(1, 2001, 1)theta_hat = np.zeros(len(N))u = np.array([])for i inrange(len(N)): u = np.append(u, np.random.uniform(0, 1)) theta_hat[i] = np.mean(np.exp(-u))plt.plot(N, theta_hat)plt.axhline(y=1- np.exp(-1), color='red', linestyle='--')plt.xlabel('n')plt.ylabel(r'$\hat{\theta}_n$')plt.title(r'Aproximação de $\theta$')plt.show()
Esse gráfico mostra a evolução da estimativa à medida que o número de variáveis aleatórias \(n\) aumenta, comparando com o valor real da integral.
11.2 Exemplo 2: Aproximando uma Probabilidade
Seja \(X \sim Gama(2,3)\). Queremos aproximar o valor de \(\mathbb{P}(X \geq 0.4)\) usando o método de Monte Carlo. Note que \[\theta:= \mathbb{P}(X \geq 0.4) = \int g(x)f(x)dx,\] em que \(g(x)=I(x \geq 0.4)\) e \(f(x)\) é a densidade da Gama(2,3). Assim, podemos aproximar a probabilidade gerada via MC.
Neste caso, o algoritmo corresponde a gerar \(X_i \sim Gama(2,3)\), defir e definir uma variável indicadora \(Y_i\) que vale 1 quando \(X_i \geq 0.4\) e 0 caso contrário. A estimativa de Monte Carlo é dada pela média dos \(Y_i\)’s:
set.seed(58)library(ggplot2)# Número de amostrasN <-50000# Geração de amostras da distribuição Gammax <-rgamma(N, shape =2, rate =3) # Usando rate = 1/scale# Cálculo de P(X >= 0.4)y <-as.integer(x >=0.4)# Estimativa via Monte Carlovalor_aproximado <-mean(y)cat("Valor aproximado via Monte Carlo:", valor_aproximado, "\n")
Valor aproximado via Monte Carlo: 0.66282
Mostrar código
# Valor real usando a função de distribuição acumulada (CDF)valor_real <-1-pgamma(0.4, shape =2, rate =3)cat("Valor real (CDF):", valor_real, "\n")
Valor real (CDF): 0.6626273
Mostrar código
import numpy as npfrom scipy.stats import gamma# Número de amostrasN =50000# Geração de amostras da distribuição Gammax = gamma.rvs(2, scale=1/3, size=N)# Cálculo de P(X >= 0.4)y = (x >=0.4).astype(int)# Estimativa via Monte Carlovalor_aproximado = np.mean(y)print("Valor aproximado via Monte Carlo:", valor_aproximado)
Valor aproximado via Monte Carlo: 0.66098
Mostrar código
# Valor real usando a função de distribuição acumulada (CDF)valor_real =1- gamma.cdf(0.4, 2, scale=1/3)print("Valor real (CDF):", valor_real)
Valor real (CDF): 0.6626272662068446
11.3 Exemplo 3: Aproximando o valor de \(\pi\)
Neste exemplo, queremos aproximar o valor de \(\pi\) utilizando o método de Monte Carlo. A ideia é gerar pontos aleatórios em um quadrado e contar quantos caem dentro de um círculo inscrito no quadrado. Vamos seguir o raciocínio a partir da geometria básica.
11.3.0.1 Geometria
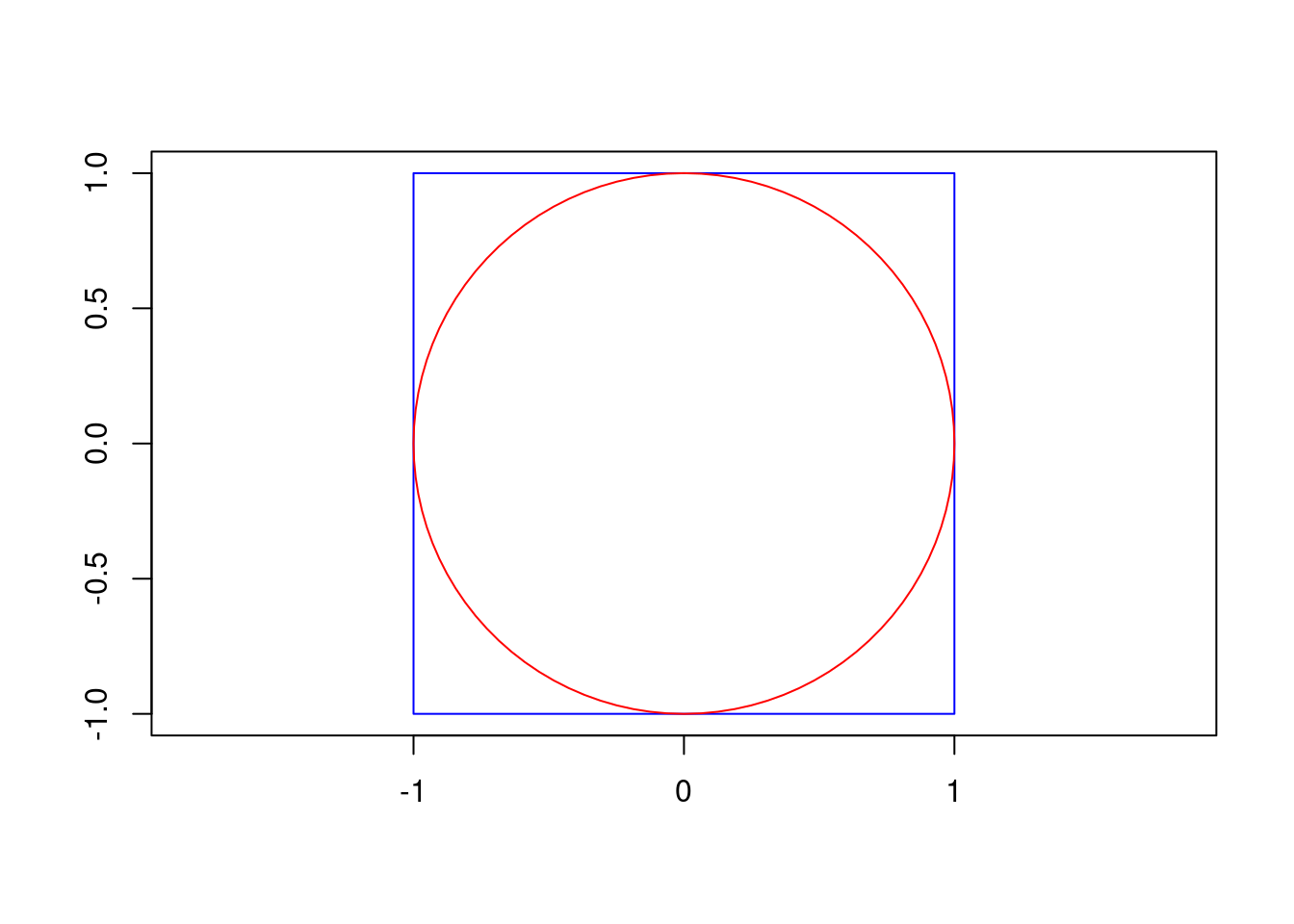
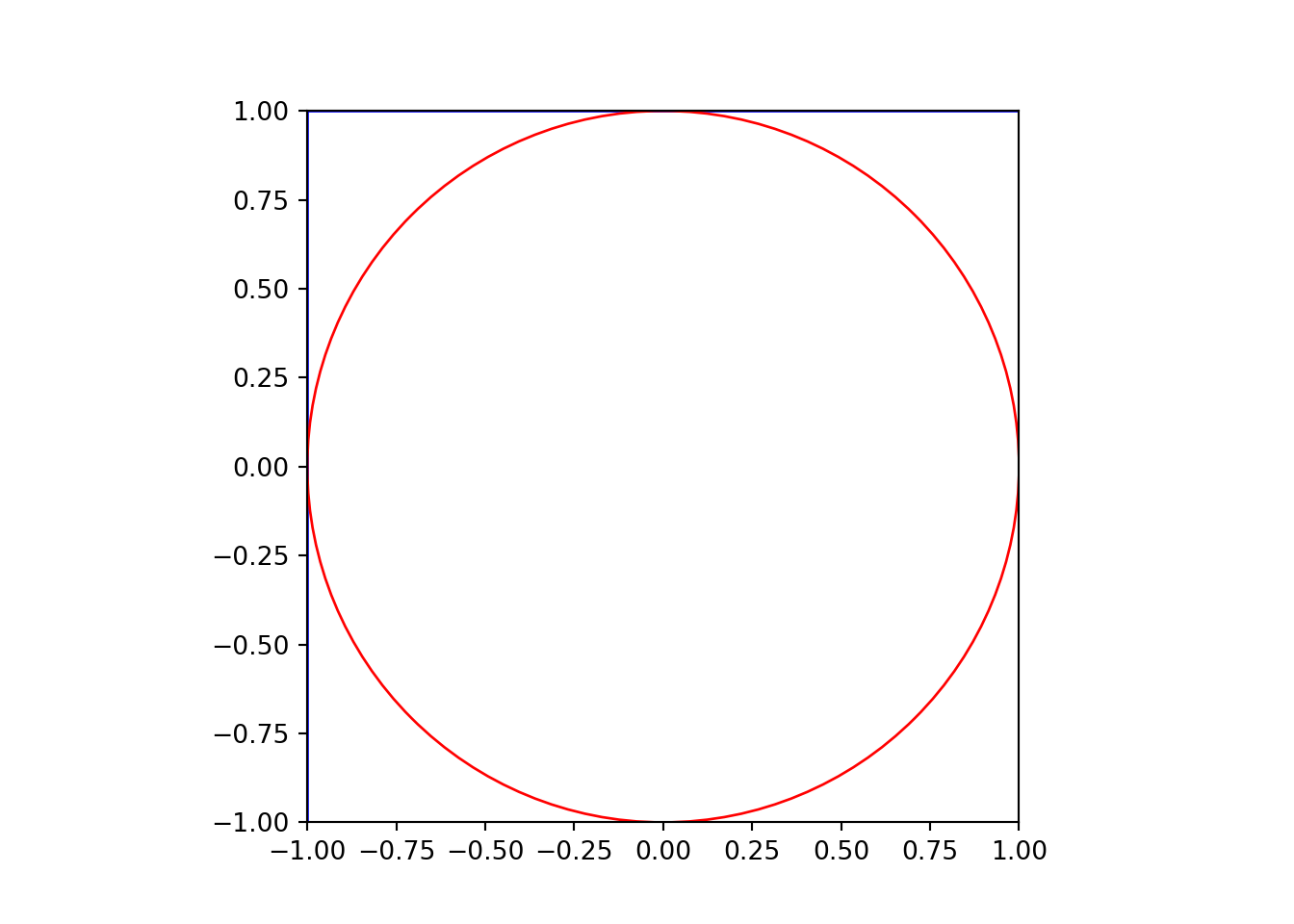
Considere um quadrado com lado 2 centrado na origem, ou seja, o quadrado vai de \((-1, -1)\) até \((1, 1)\).
Dentro deste quadrado, inscreva um círculo de raio 1, também centrado na origem.
A área do quadrado é \(4\) (já que \(2 \times 2 = 4\)) e a área do círculo é \(\pi \cdot r^2 = \pi \cdot 1^2 = \pi\).
A razão entre a área do círculo e a área do quadrado é dada por:
\[
\frac{\text{Área do círculo}}{\text{Área do quadrado}} = \frac{\pi}{4}
\]
import matplotlib.pyplot as pltfrom matplotlib.patches import Rectangle, Circle# Configura o gráficofig, ax = plt.subplots()ax.set_aspect('equal') # Define o aspecto como 1:1 (quadrado)ax.set_xlim(-1, 1)
(-1.0, 1.0)
Mostrar código
ax.set_ylim(-1, 1)
(-1.0, 1.0)
Mostrar código
ax.set_xlabel('')ax.set_ylabel('')# Desenha o retângulorect = Rectangle((-1, -1), 2, 2, edgecolor='blue', facecolor='none')ax.add_patch(rect)# Desenha o círculocircle = Circle((0, 0), 1, edgecolor='red', facecolor='none')ax.add_patch(circle)# Mostra o gráficoplt.show()
Para estimar \(\pi\) usando Monte Carlo, procedemos da seguinte forma:
Geramos pontos aleatórios \((x, y)\) no quadrado \([-1, 1] \times [-1, 1]\).
Verificamos se cada ponto está dentro do círculo, o que ocorre se \(x^2 + y^2 \leq 1\).
A fração de pontos que caem dentro do círculo aproxima a razão \(\frac{\pi}{4}\).
Multiplicamos essa fração por 4 para obter uma estimativa de \(\pi\).
11.3.0.2 Matemática do Estimador
Formalmente, se \((X,Y) \sim Unif(-1,1) \times Unif(-1,1)\) e \(g(x,y)=I(\text{(x,y) está no círculo})\), temos que \[\theta:=\int g(x,y)f(x,y) dxdy = \frac{\text{Área do círculo}}{\text{Área do quadrado}} = \frac{\pi}{4} \] Assim, se \((X_i,Y_i)\) é um ponto gerado uniformemente dentro do quadrado, o estimador de Monte Carlo para \(\frac{\pi}{4}\) é dado por: \[
\hat{\theta}_n = \frac{1}{n} \sum_{i=1}^n g(x_i,y_i)= \frac{1}{n} \sum_{i=1}^n z_i,
\] em que \(z_i = 1\) se o ponto \(i\) está dentro do círculo (i.e., se \(x_i^2 + y_i^2 \leq 1\)) e \(z_i = 0\) caso contrário.
Multiplicando por 4, obtemos a estimativa de \(\pi\):
Ou seja, à medida que o número de pontos simulados \(n\) aumenta, a estimativa \(\hat{\pi}_n\) convergirá para o valor verdadeiro de \(\pi\).
Implementação
Os trechos de código fornecidos em R e Python simulam esse processo, gerando \(n\) pontos e calculando a aproximação de \(\pi\) com base nos pontos que caem dentro do círculo. Além disso, são gerados gráficos que mostram como a estimativa de \(\pi\) melhora conforme o número de simulações aumenta, evidenciando a convergência mencionada.
Agora que todos os detalhes matemáticos do exemplo estão claros, o código para simulação pode ser executado para observar a aproximação prática de \(\pi\).
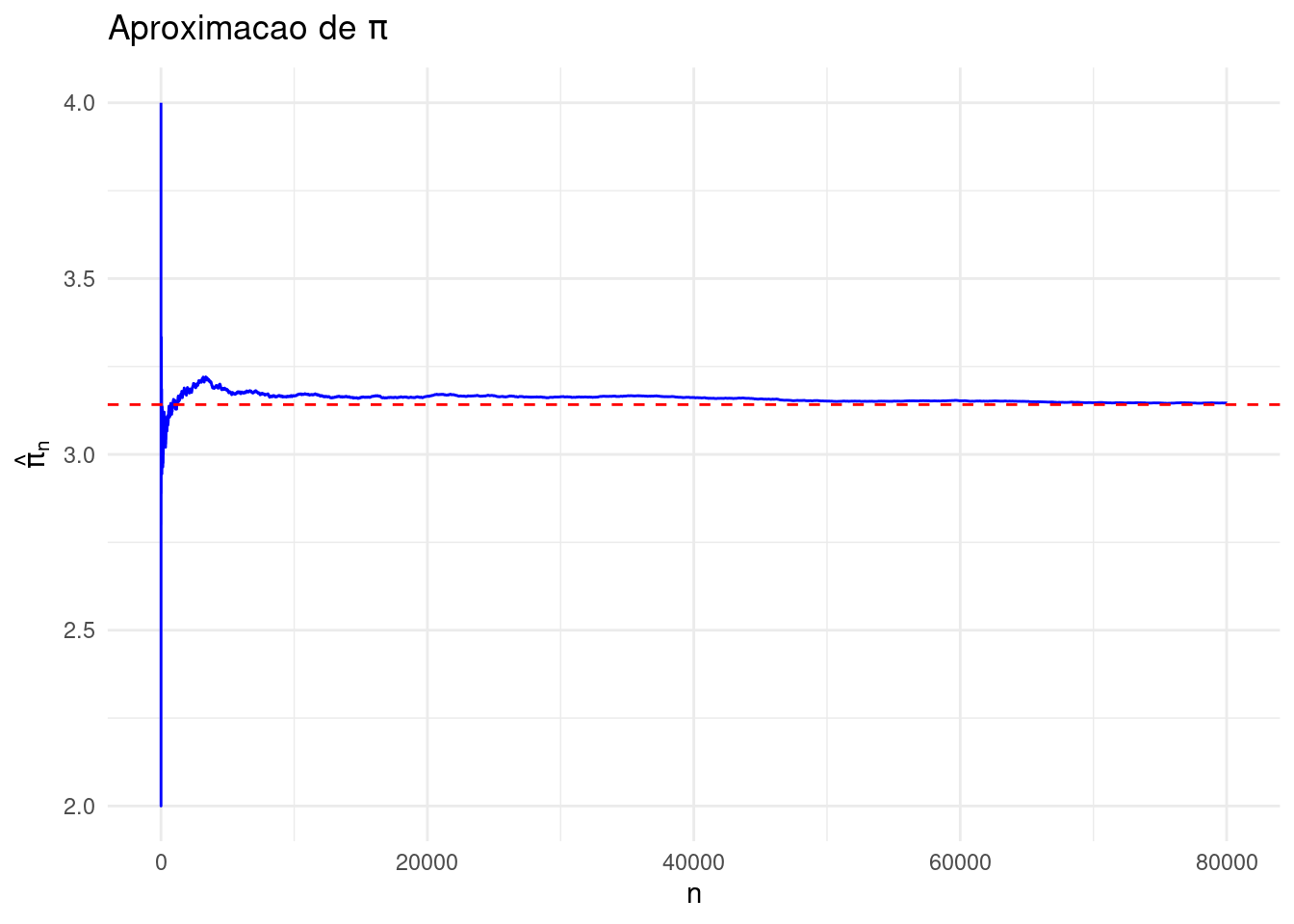
set.seed(459)library(ggplot2)N <-1:80000z <-numeric(length(N))# Loop para gerar os pontos e verificar se estão dentro do círculofor (i inseq_along(N)) { x <-2*runif(1) -1 y <-2*runif(1) -1 z[i] <- (x^2+ y^2<=1)}# Cálculo da estimativa de pitheta_hat <-cumsum(z) / Npi_hat <- theta_hat *4# Criando o dataframe para o ggplotdf <-data.frame(N = N, pi_hat = pi_hat)# Plotar o gráfico usando ggplot2ggplot(df, aes(x = N, y = pi_hat)) +geom_line(color ="blue") +geom_hline(yintercept = pi, color ="red", linetype ="dashed") +labs(x ="n", y =expression(hat(pi)[n]), title =expression(Aproximacao~de~pi)) +theme_minimal()
Mostrar código
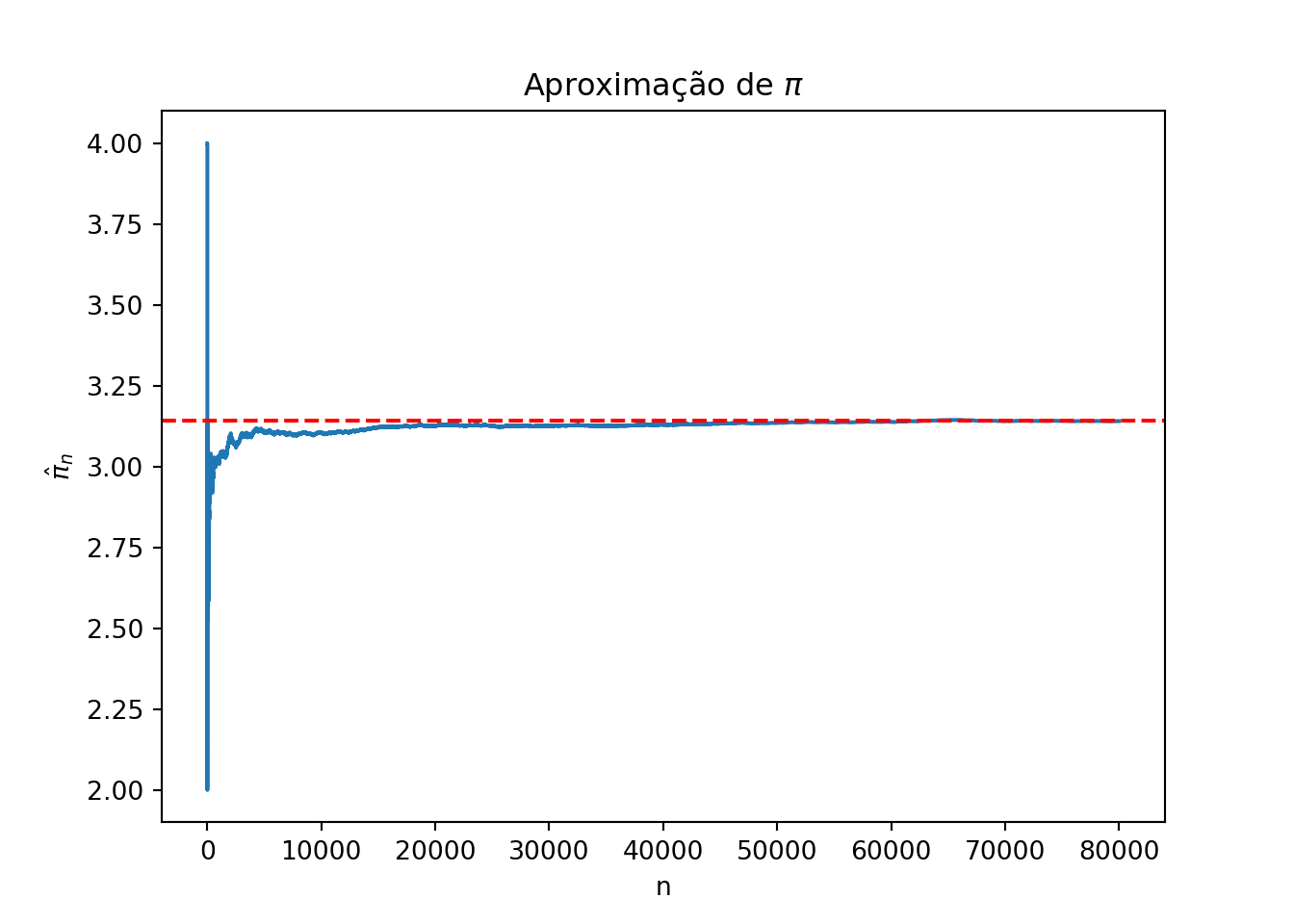
import numpy as npimport matplotlib.pyplot as pltnp.random.seed(459)N = np.arange(1, 80001, 1)z = np.zeros(len(N))for i inrange(len(N)): x =2* np.random.uniform(0, 1) -1 y =2* np.random.uniform(0, 1) -1 z[i] = (x**2+ y**2<=1)theta_hat = np.cumsum(z) / Npi_hat = theta_hat *4plt.plot(N, pi_hat)plt.axhline(y=np.pi, color='red', linestyle='--')plt.xlabel('n')plt.ylabel(r'$\hat{\pi}_n$')plt.title(r'Aproximação de $\pi$')plt.show()
Esse gráfico mostra como a estimativa de \(\pi\) melhora conforme o número de pontos simulados \(n\) aumenta.
11.4 Intervalos de Confiança para Estimativas de Monte Carlo
O Método de Monte Carlo possibilita quantificar a incerteza em nossas estimativas. Para isso, podemos utilizar intervalos de confiança.
Suponha que temos uma sequência de amostras \(X_1, X_2, \dots, X_n\) de uma variável aleatória \(X\), e calculamos a média amostral \(\hat{\theta}_n = \frac{1}{n} \sum_{i=1}^n g(X_i)\). Pelo Teorema Central do Limite, sabemos que, para \(n\) suficientemente grande, a média amostral \(\hat{\theta}_n\) é aproximadamente normalmente distribuída:
onde \(z_{\alpha/2}\) é o quantil da distribuição normal padrão associado à probabilidade \(\alpha/2\) e \(\hat{\sigma}\) é a estimativa da variância de \(g(X)\), obtida a partir das amostras.
Pseudo-Algoritmo para construir um intervalo de confiança:
Gere \(X_1, \dots, X_n\) amostras i.i.d. da v.a. \(X\).
set.seed(0)N <-10000# número de amostrasz <-numeric(N)# Loop para gerar os pontos e verificar se estão dentro do círculofor (i in1:N) { x <-2*runif(1) -1 y <-2*runif(1) -1 z[i] <- (x^2+ y^2<=1)}# Estimativa de pitheta_hat <-mean(z)pi_hat <- theta_hat *4cat("Estimativa de pi:", pi_hat, "\n")
Estimativa de pi: 3.1308
Mostrar código
# Cálculo da variância e intervalo de confiançasigma_hat <-sqrt(var(z) / N)alpha <-0.05# Nível de significânciaz_alpha2 <-qnorm(1- alpha /2)# Intervalo de confiançaIC <-c(theta_hat - z_alpha2 * sigma_hat, theta_hat + z_alpha2 * sigma_hat) *4cat("Intervalo de confiança para pi:", IC, "\n")
Intervalo de confiança para pi: 3.098466 3.163134
Mostrar código
import numpy as npfrom scipy.stats import norm# Semente para reproduçãonp.random.seed(0)N =10000# número de amostrasz = np.zeros(N)# Loop para gerar os pontos e verificar se estão dentro do círculofor i inrange(N): x =2* np.random.uniform(0, 1) -1 y =2* np.random.uniform(0, 1) -1 z[i] = (x**2+ y**2<=1)# Estimativa de pitheta_hat = np.mean(z)pi_hat = theta_hat *4print("Estimativa de pi:", pi_hat)
Estimativa de pi: 3.1228
Mostrar código
# Cálculo da variância e intervalo de confiançasigma_hat = np.sqrt(np.var(z) / N)alpha =0.05# Nível de significânciaz_alpha2 = norm.ppf(1- alpha /2)# Intervalo de confiançaIC = (theta_hat - z_alpha2 * sigma_hat, theta_hat + z_alpha2 * sigma_hat)IC = [i *4for i in IC]print("Intervalo de confiança para pi:", IC)
Intervalo de confiança para pi: [np.float64(3.090360848359833), np.float64(3.1552391516401666)]
Neste caso, o intervalo de confiança construído em torno da estimativa \(\hat{\pi}_n\) oferece uma ideia de quão próxima nossa estimativa está do valor verdadeiro de \(\pi\), com uma certa confiança.
11.5 Exemplo 4: Problema das Figurinhas
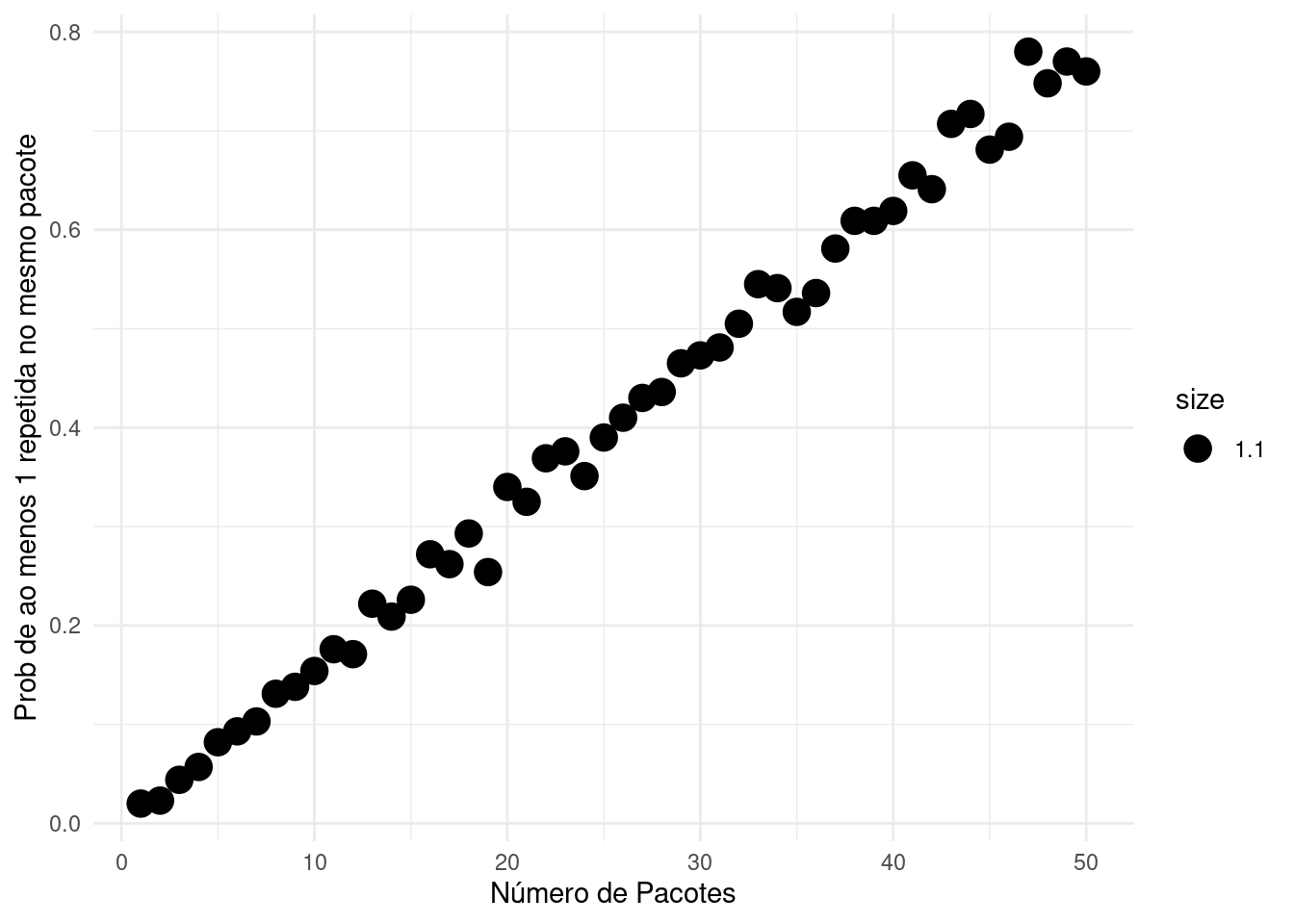
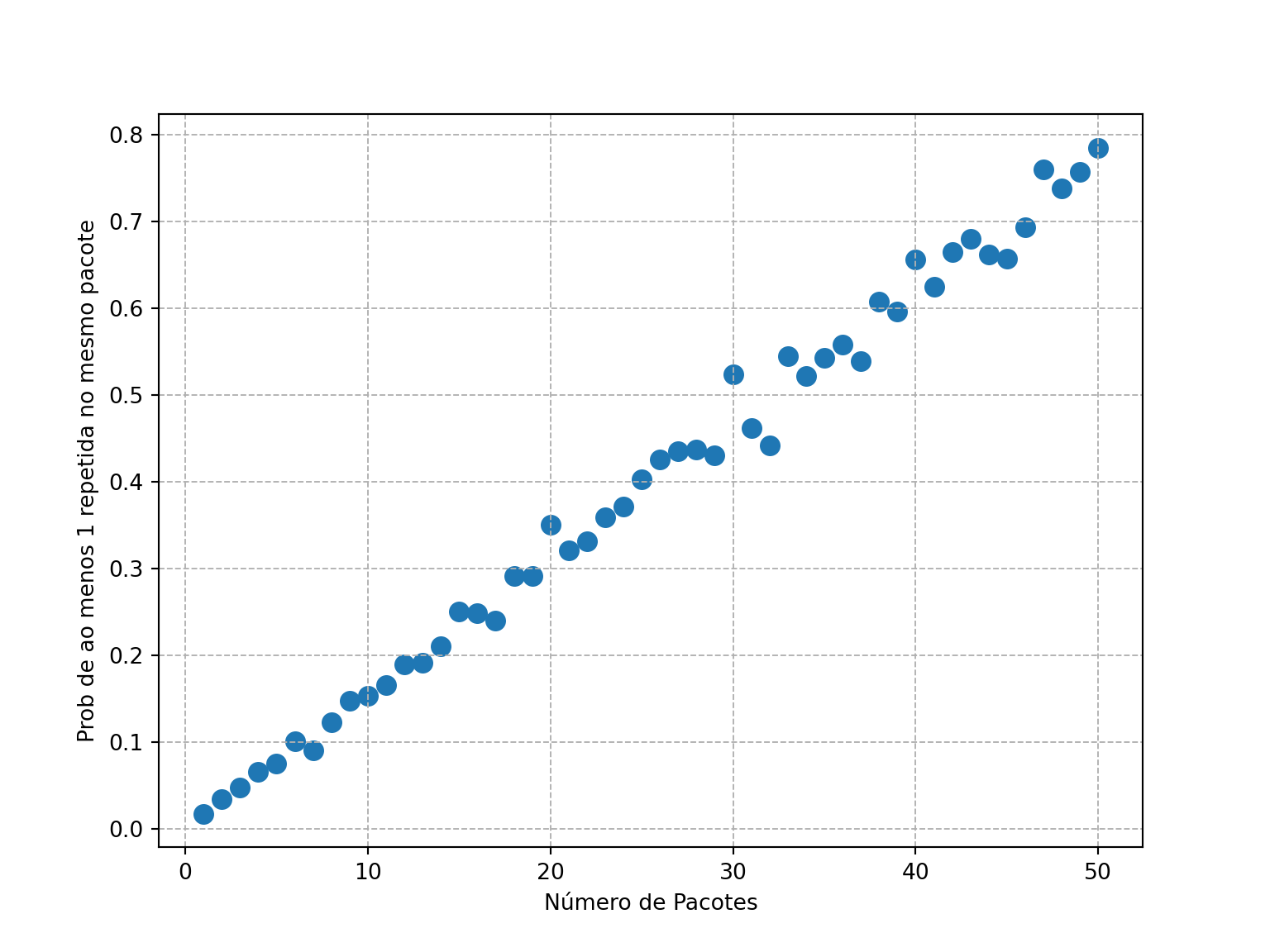
Um colecionador está juntando figurinhas para completar um álbum da Copa. Qual é a probabilidade de que, ao comprar \(n\) pacotes, pelo menos um deles contenha duas ou mais figurinhas iguais? Durante o curso de probabilidade, você aprenderá como calcular essa probabilidade. Outra abordagem possível é o uso do método de Monte Carlo. Nesse caso, simulamos a compra de \(n\) pacotes, cada um com 5 figurinhas, de um total de 640 figurinhas disponíveis no álbum. Repetimos essa simulação \(B=1000\) vezes e contamos quantas vezes ocorreu pelo menos uma repetição de figurinhas em algum dos pacotes. A proporção de simulações com repetições é a estimativa de Monte Carlo da probabilidade que estamos interessados em calcular.
dados <-data.frame(probCoincidencia = probCoincidencia, nPacotes = nPacotes)library(ggplot2)ggplot(dados, aes(x = nPacotes, y = probCoincidencia)) +geom_point(aes(size =1.1)) +xlab("Número de Pacotes") +ylab("Prob de ao menos 1 repetida no mesmo pacote") +theme(legend.position ="none")+theme_minimal()
Mostrar código
import pandas as pdimport matplotlib.pyplot as plt# Criação do DataFramedados = pd.DataFrame({'nPacotes': nPacotes, 'probCoincidencia': probCoincidencia})# Criação do gráficoplt.figure(figsize=(8, 6))plt.scatter(dados['nPacotes'], dados['probCoincidencia'], s=70) # 's' ajusta o tamanho dos pontosplt.xlabel('Número de Pacotes')plt.ylabel('Prob de ao menos 1 repetida no mesmo pacote')plt.grid(True, which='both', linestyle='--', linewidth=0.7)plt.gca().set_facecolor('white') # Para seguir o tema minimalistaplt.show()
Simulação para completar o álbum
Uma segunda pergunta que também podemos responder via simulação é: quantos pacotes necessitamos em média para completar o álbum? A solução estimada pode ser obtida com o código abaixo:
cat("Probabilidade de precisar de mais de 800 pacotes: ", mean(numeroPacotes >800) *100, "%", sep ="")
Probabilidade de precisar de mais de 800 pacotes: 69.3%
Mostrar código
cat("Probabilidade de precisar de mais de 1000 pacotes: ", mean(numeroPacotes >1000) *100, "%", sep ="")
Probabilidade de precisar de mais de 1000 pacotes: 23.2%
Mostrar código
prob_mais_800 = np.mean(numeroPacotes >800) *100prob_mais_1000 = np.mean(numeroPacotes >1000) *100print(f"Probabilidade de precisar de mais de 800 pacotes: {prob_mais_800}%")
Probabilidade de precisar de mais de 800 pacotes: 70.5%
Mostrar código
print(f"Probabilidade de precisar de mais de 1000 pacotes: {prob_mais_1000}%")
Probabilidade de precisar de mais de 1000 pacotes: 20.599999999999998%
11.6 Exercícios
Exercício 1.
Utilize o método de Monte Carlo para aproximar a integral \[
I = \int_0^{10} \sin(x^2) \, dx
\]
Forneça um intervalo de confiança para avaliar a precisão da estimativa.
Exercício 2.
Utilize o método de Monte Carlo para aproximar a integral \[
I = \int_1^{\infty} \frac{1}{x^3} \, dx
\]
Forneça um intervalo de confiança para avaliar a precisão da estimativa.
Exercício 3.
Seja \(X \sim \text{Exp}(\lambda)\) com \(\lambda = 2\). Estime a esperança \(\mathbb{E}[X^2]\) utilizando o método de Monte Carlo. Forneça um intervalo de confiança para avaliar a precisão da estimativa. Compare com o valor real dessa quantidade.
Exercício 4.
Considere que \(X\) tem distribuição Normal(0,1) e \(Y\) tem distribuição Gamma(1,1). Estime \(P(X\times Y > 3)\). Forneça um intervalo de confiança para avaliar a precisão da estimativa.