O Método de Monte Carlo, embora funcione, nem sempre é eficiente. Veremos a seguir um exemplo disso.
13.1 Exemplo 1: Estimativa de \(\mathbb{P}(Z > 4.5)\)
Neste exemplo, vamos estimar a probabilidade \(\mathbb{P}(Z > 4.5)\) onde \(Z \sim N(0,1)\). Este é um evento raro, com probabilidade pequena. O valor exato dessa probabilidade é: \[
\log(\mathbb{P}(Z > 4.5)) = -12.59242
\] Aplicaremos o método de Monte Carlo simulando \(n = 100.000\) valores de \(Z \sim N(0,1)\) e calculando a proporção dos valores que são maiores que 4.5.
set.seed(0)# Valor exato de P(Z > 4.5)valor_exato <-log(pnorm(4.5, 0, 1, lower.tail =FALSE))cat("Valor exato (log(P(Z > 4.5))):", valor_exato, "\n")
Valor exato (log(P(Z > 4.5))): -12.59242
Mostrar código
# Simulação Monte Carlon <-100000z <-rnorm(n, 0, 1)# Estimativa Monte Carlo de P(Z > 4.5)p_estimada <-mean(1* (z >4.5))cat("Estimativa Monte Carlo de P(Z > 4.5):", p_estimada, "\n")
Estimativa Monte Carlo de P(Z > 4.5): 0
Mostrar código
# Logaritmo da estimativa Monte Carlolog_p_estimada <-log(p_estimada)cat("Logaritmo da estimativa Monte Carlo:", log_p_estimada, "\n")
Logaritmo da estimativa Monte Carlo: -Inf
Mostrar código
import numpy as npfrom scipy.stats import norm# Valor exato de P(Z > 4.5)valor_exato = np.log(norm.sf(4.5)) # sf is the survival function, equivalent to (1 - cdf)print(f"Valor exato (log(P(Z > 4.5))): {valor_exato}")
Valor exato (log(P(Z > 4.5))): -12.592419735713081
Mostrar código
# Simulação Monte Carlon =100000z = np.random.normal(0, 1, n)# Estimativa Monte Carlo de P(Z > 4.5)p_estimada = np.mean(z >4.5)print(f"Estimativa Monte Carlo de P(Z > 4.5): {p_estimada}")
Estimativa Monte Carlo de P(Z > 4.5): 0.0
Mostrar código
# Logaritmo da estimativa Monte Carlolog_p_estimada = np.log(p_estimada)print(f"Logaritmo da estimativa Monte Carlo: {log_p_estimada}")
Logaritmo da estimativa Monte Carlo: -inf
O método de Monte Carlo exige uma grande quantidade de amostras para fornecer uma estimativa precisa devido à raridade do evento \(Z > 4.5\). A abordagem pode se tornar ineficiente para eventos raros.
13.2 Amostragem por Importância
A Amostragem por Importância é uma técnica que nos permite simular valores \(Y_1, \dots, Y_n\) a partir de uma densidade auxiliar \(g(y)\).
A ideia chave é que, se \(X\) tem densidade \(f(x)\), a esperança \(\mathbb{E}[h(X)]\) pode ser reescrita como:
\[
\mathbb{E}[h(X)] = \int h(x) f(x) dx = \int h(x) \frac{f(x)}{g(x)} g(x) dx = \mathbb{E}\left[ h(Y) \frac{f(Y)}{g(Y)} \right],
\] em que \(Y\) tem densidade \(g\). Isso vale desde que \(g\) possua suporte tão ou mais amplo que a região de integração. Assim, podemos estimar \(\mathbb{E}[h(X)]\) usando \(n\) valores simulados de \(Y\) independentemente pela fórmula:
Note que os pesos \(w_i = \frac{f(y_i)}{g(y_i)}\) ajustam a importância de cada amostra, tornando a simulação mais eficiente.
13.2.1 Revistando o Exemplo 1 via Amostragem por Importância
Para melhorar a eficiência no Exemplo 1, vamos agora usar Amostragem por Importância. Em vez de simular diretamente de \(Z \sim N(0,1)\), simulamos de uma distribuição exponencial truncada \(Exp(1)\) a partir de 4.5. A densidade de importância é: \[
g(y) = e^{-(y - 4.5)}, \quad y > 4.5
\]
O estimador de Monte Carlo ponderado é, portanto, \[
\hat{\theta}_n = \frac{1}{n} \sum_{i=1}^n \frac{f(y_i)}{g(y_i)}I(y_i>4.5)=\frac{1}{n} \sum_{i=1}^n \frac{f(y_i)}{g(y_i)},
\] onde \(f(y_i)\) é a densidade da normal \(N(0,1)\). Aqui está o código equivalente em Python no formato solicitado:
n <-100# Gerar n valores da distribuição exponencial truncaday <-rexp(n) +4.5# Estimativa por importânciaestimativa_importancia <-mean(dnorm(y) /exp(-(y -4.5)))cat("Estimativa por amostragem por importância:", estimativa_importancia, "\n")
Estimativa por amostragem por importância: 3.723979e-06
Mostrar código
# Logaritmo da estimativa por importâncialog_estimativa_importancia <-log(estimativa_importancia)cat("Logaritmo da estimativa por amostragem por importância:", log_estimativa_importancia, "\n")
Logaritmo da estimativa por amostragem por importância: -12.50072
Mostrar código
import numpy as npfrom scipy.stats import expon, normn =100# Gerar n valores da distribuição exponencial truncaday = expon.rvs(scale=1, size=n) +4.5# Estimativa por importânciaestimativa_importancia = np.mean(norm.pdf(y) / np.exp(-(y -4.5)))print(f"Estimativa por amostragem por importância: {estimativa_importancia}")
Estimativa por amostragem por importância: 3.329630733431657e-06
Mostrar código
# Logaritmo da estimativa por importâncialog_estimativa_importancia = np.log(estimativa_importancia)print(f"Logaritmo da estimativa por amostragem por importância: {log_estimativa_importancia}")
Logaritmo da estimativa por amostragem por importância: -12.612649150982133
Com essa técnica, concentramos as simulações na região relevante, melhorando a eficiência da estimativa para eventos raros.
13.3 Exemplo 2: Estimativa de \(\mathbb{E}[\sqrt{X}]\) com Amostragem por Importância
Agora, vamos estimar \(\theta = \mathbb{E}[\sqrt{X}]\) onde \(X \sim Exp(1)\). Sabemos que o valor exato desta integral é \(\sqrt{\pi}/2\).
13.3.1 Aproximação via Monte Carlo
Vamos simular \(X \sim Exp(1)\) e calcular a média de \(\sqrt{X}\) diretamente:
# Valor exato da integralreal <-sqrt(pi) /2cat("Valor exato:", real, "\n")
Valor exato: 0.8862269
Mostrar código
# Número de amostrasn <-10000# Geração de amostras da distribuição exponencialx <-rexp(n, 1)# Estimativa Monte Carlo para E[sqrt(X)]estimativa_mc <-mean(sqrt(x))cat("Estimativa Monte Carlo de E[sqrt(X)]:", estimativa_mc, "\n")
Estimativa Monte Carlo de E[sqrt(X)]: 0.8842487
Mostrar código
# Variância da estimativavariancia_mc <-var(sqrt(x))cat("Variância da estimativa:", variancia_mc, "\n")
Variância da estimativa: 0.2075346
Mostrar código
import numpy as npfrom scipy.stats import expon# Valor exato da integralreal = np.sqrt(np.pi) /2print(f"Valor exato: {real}")
Valor exato: 0.8862269254527579
Mostrar código
# Número de amostrasn =10000# Geração de amostras da distribuição exponencialx = expon.rvs(scale=1, size=n)# Estimativa Monte Carlo para E[sqrt(X)]estimativa_mc = np.mean(np.sqrt(x))print(f"Estimativa Monte Carlo de E[sqrt(X)]: {estimativa_mc}")
Estimativa Monte Carlo de E[sqrt(X)]: 0.8832009971066371
Mostrar código
# Variância da estimativavariancia_mc = np.var(np.sqrt(x), ddof=1)print(f"Variância da estimativa: {variancia_mc}")
Variância da estimativa: 0.213930257711554
13.3.2 Aproximação via Amostragem por Importância
Agora, vamos usar a Amostragem por Importância com duas distribuições diferentes para melhorar a eficiência.
Usando \(Y = |Z|\), onde \(Z \sim N(0,1)\):
A densidade de importância combinada é: \[
g(y) = dnorm(y) + dnorm(-y)
\]
# Gerando amostras de uma distribuição normal absolutaz <-abs(rnorm(n))# Função de densidade combinada g(x)g <-function(x) {return(dnorm(x) +dnorm(-x))}# Estimativa por amostragem por importânciaestimativa_importancia <-mean((sqrt(z)) *dexp(z, 1) /g(z))cat("Estimativa por amostragem por importância:", estimativa_importancia, "\n")
Estimativa por amostragem por importância: 1.038467
Mostrar código
# Variância da estimativa por amostragem por importânciavariancia_importancia <-var((sqrt(z)) *dexp(z, 1) /g(z))cat("Variância da estimativa por amostragem por importância:", variancia_importancia, "\n")
Variância da estimativa por amostragem por importância: 367.4869
Mostrar código
import numpy as npfrom scipy.stats import norm, expon# Definir o tamanho da amostran =10000# Altere conforme necessário# Gerando amostras de uma distribuição normal absolutaz = np.abs(np.random.normal(size=n))# Função de densidade combinada g(x)def g(x):return norm.pdf(x) + norm.pdf(-x)# Estimativa por amostragem por importânciaestimativa_importancia = np.mean((np.sqrt(z)) * expon.pdf(z, scale=1) / g(z))print("Estimativa por amostragem por importância:", estimativa_importancia)
Estimativa por amostragem por importância: 0.8269444372337743
Mostrar código
# Variância da estimativa por amostragem por importânciavariancia_importancia = np.var((np.sqrt(z)) * expon.pdf(z, scale=1) / g(z))print("Variância da estimativa por amostragem por importância:", variancia_importancia)
Variância da estimativa por amostragem por importância: 3.3092709373223057
Usando \(Y = |Z|\), onde \(Z \sim Cauchy(0,1)\):
A densidade de importância combinada agora é: \[
g2(y) = dcauchy(y) + dcauchy(-y)
\]
# Gerando amostras de uma distribuição Cauchy absolutaz <-abs(rcauchy(n))# Função de densidade combinada g2(x) para a Cauchyg2 <-function(x) {return(dcauchy(x) +dcauchy(-x))}# Estimativa por amostragem por importância usando Cauchyestimativa_importancia_cauchy <-mean((sqrt(z)) *dexp(z, 1) /g2(z))cat("Estimativa por amostragem por importância (Cauchy):", estimativa_importancia_cauchy, "\n")
Estimativa por amostragem por importância (Cauchy): 0.885894
Mostrar código
# Variância da estimativa por amostragem por importância usando Cauchyvariancia_importancia_cauchy <-var((sqrt(z)) *dexp(z, 1) /g2(z))cat("Variância da estimativa por amostragem por importância (Cauchy):", variancia_importancia_cauchy, "\n")
Variância da estimativa por amostragem por importância (Cauchy): 0.1985572
Mostrar código
import numpy as npfrom scipy.stats import cauchy, expon# Gerando amostras de uma distribuição Cauchy absolutaz = np.abs(cauchy.rvs(size=n))# Função de densidade combinada g2(x) para a Cauchydef g2(x):return cauchy.pdf(x) + cauchy.pdf(-x)# Estimativa por amostragem por importância usando Cauchyestimativa_importancia_cauchy = np.mean(np.sqrt(z) * expon.pdf(z, scale=1) / g2(z))print(f"Estimativa por amostragem por importância (Cauchy): {estimativa_importancia_cauchy}")
Estimativa por amostragem por importância (Cauchy): 0.8853104584819294
Mostrar código
# Variância da estimativa por amostragem por importância usando Cauchyvariancia_importancia_cauchy = np.var(np.sqrt(z) * expon.pdf(z, scale=1) / g2(z), ddof=1)print(f"Variância da estimativa por amostragem por importância (Cauchy): {variancia_importancia_cauchy}")
Variância da estimativa por amostragem por importância (Cauchy): 0.19450904194031554
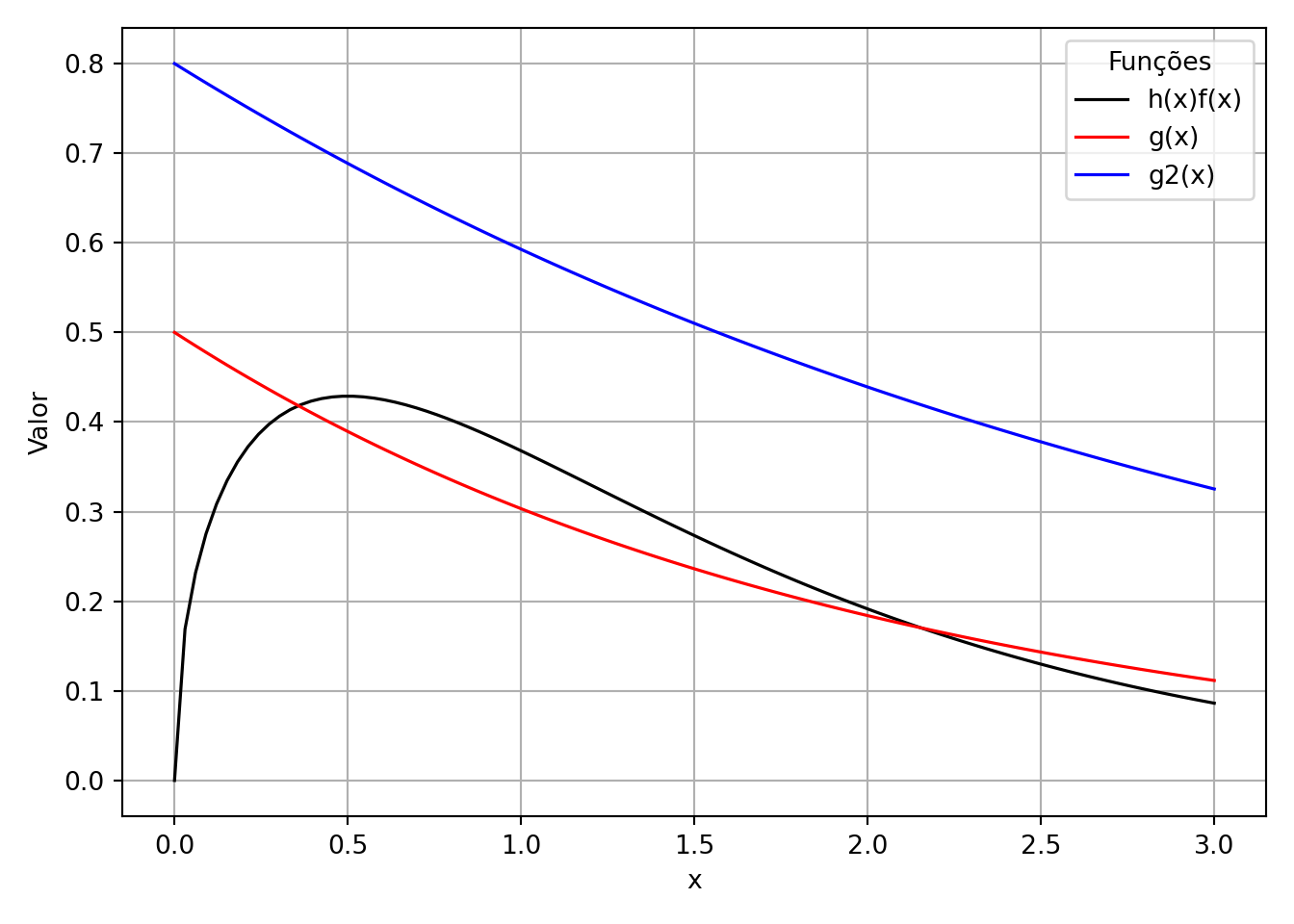
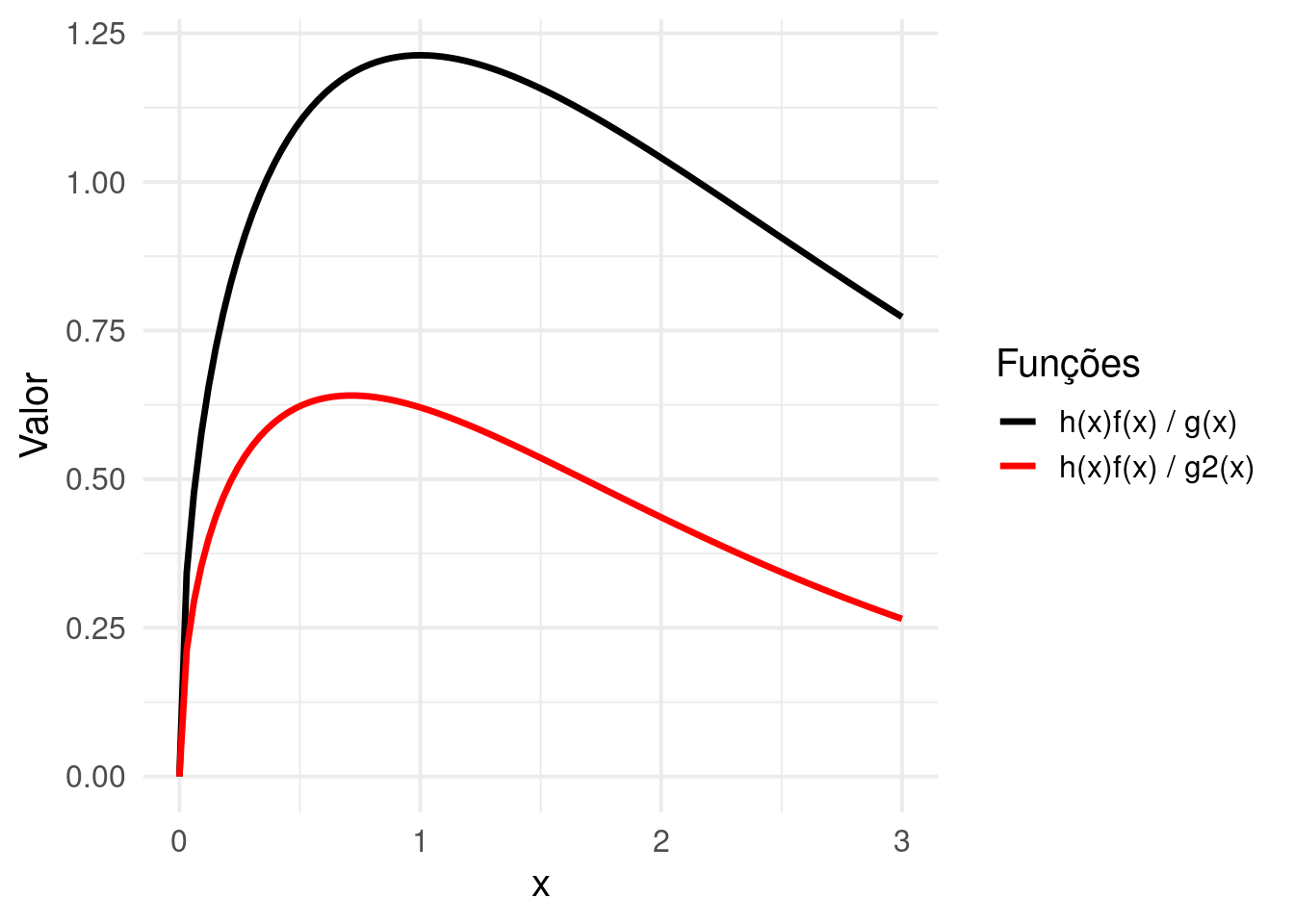
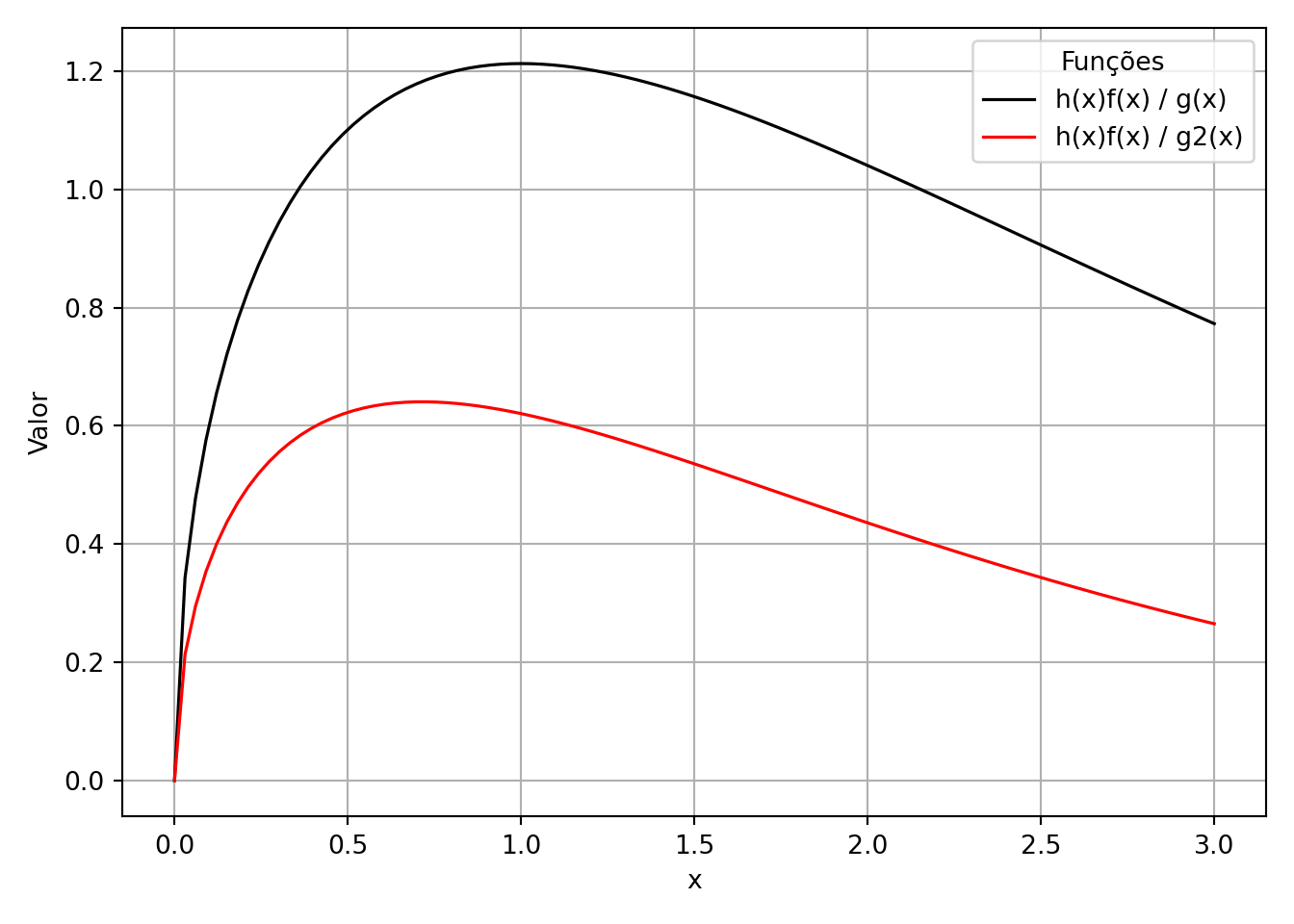
Podemos visualizar as funções de densidade \(h(x) f(x)\) e as funções de importância \(g(x)\) e \(g2(x)\) para entender melhor a escolha das distribuições de importância.
Esses gráficos mostram como as diferentes escolhas de distribuições de importância afetam a função ponderada, ajudando a reduzir a variância do estimador.
13.4 Exercícios
Exercício 1. Usando a Amostragem por Importância, estime a probabilidade de que uma variável aleatória \(Z \sim N(0,1)\) seja maior que 5.0. Compare os resultados obtidos com a amostragem direta usando Monte Carlo simples e discuta a eficiência da Amostragem por Importância em relação ao método direto.
Exercício 2. Estime o valor da integral \(\int_0^2 \sqrt{x} e^{-x} dx\) utilizando a Amostragem por Importância com duas distribuições de importância diferentes. Justifique a escolha das distribuições e compare a eficiência de cada uma.
Exercício 3. Utilize a Amostragem por Importância para estimar \(\mathbb{E}[\log(1 + X)]\), onde \(X \sim Exp(1)\). Escolha uma densidade auxiliar apropriada para melhorar a eficiência da estimativa e justifique sua escolha. Compare os resultados com a aproximação via Monte Carlo simples.